Here is a diagram showing similarities between documents; this is an actual set of physics lab assignments from a large university.
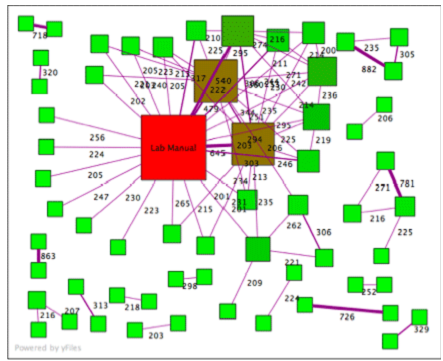
Each node (square) in the graph is a document. Each edge (line) connects two documents based on the number of 6-word phrases they have in common. To reduce noise, only documents sharing more than 200 6-word phrases are shown. The red square is the lab manual, and the brown squares are two sample lab reports that were distributed in class. (Apparently many students 'borrowed' heavily from these documents.) But if we look carefully, we notice that several papers share a large number of phrases in common with each other and with no other documents. For example, a pair at the top left share 718, a pair at the top right show 882, and a pair on the lower left share 863 6-word phrases in common. It's likely that those people turned in essentially the same lab report or copied from each other. Your program will read through a directory full of files and identify pairs of files that share more than 200 6-word phrases, as a means of detecting copied work.
It's important to understand what we mean by "6-word phrases." It's not just looking at 6 words, then the next 6, etc.; after all, even plagiarists are smarter than that. A 6-word phrase is a word and the following 5 words, for each word with at least 5 words after it. So, for example, the text:
Now is the time for all good men to come to the aid of their country.
Contains the 6-word phrases:
Now is the time for all
is the time for all good
the time for all good men
time for all good men to
...and so on.
Thus, a single extended passage can generate many duplicates. On the other hand, a sentence that happens to begin with "Now is the time..." will be less likely to generate more than a few 'hits' as duplicate phrases. For our purposes, upper- or lower-case doesn't matter, nor does punctuation.