Reference no: EM131096936
10-701: Machine Learning - Midterm Solutions
Q1. Probability and Density Estimation
1. If two binary random variables X and Y are independent, are X¯ (X¯ is the complement of X) and Y also independent? Prove your claim.
2. There are two coins C1 and C2. C1 has a equal prior on a head (H=1) or tail (T=0) and the fate of C2 is dependent on C1. If C1 is a head, C2 will be a head with probability 0.7. If C1 is a tail, C2 will be a head with probability 0.5. C1 and C2 are tossed in sequence once, and the observed sum of the two coins, S = C1 + C2, is 1. What is the probability that C1=T and C2=H (Hint: use Bayes theorem)?
3. We estimate the head probability θ of a coin from the results of N flips. We use pseudo-counts to influence the "fairness" of the coin. This is equivalent to using which distribution as a prior for θ.
4. Assume we computed the parameters for a Naive Bayes classifier. How can we use these parameters to compute the density P(X) of an observed vector X = {x1, x2, . . . ,xn}?
Q2. K-Nearest Neighbors Classification
Consider K-NN using Euclidean distance on the following data set (each point belongs to one of two classes: + and o).
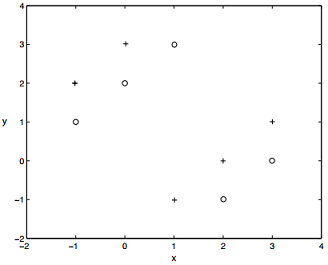
1. What is the leave one out cross validation error when using 1-NN?
2. Which of the following values of k leads to the minimum number of validation errors: 3, 5 or 9? What is the error for that k?
Q3. Linear Regression
1. We would like to use the following regression function:
y = w2x + wx (1)
where x is a single value variable. Given a set of training data points {(xi, yi)} derive a solution for w. Simplify as much as you can.
2. We would like to compare the regression model used in (1) to a the following regression model:
y = wx
(a) Given limited training data, which model would fit the training data better:
i. Model 1
ii. Model 2
iii. Both will fit the data equally well
iv. Impossible to tell
(b) Given limited training data, which model would fit the test data better:
i. Model 1
ii. Model 2
iii. Both will fit the data equally well
iv. Impossible to tell
Q4. Logistic Regression
1. Logistic regression is named after the log-odds of success (the logit of the probability) defined as
Ln(P[Y = 1|X = x]/P[Y = 0|X = x])
Show that log-odds of success is a linear function of x.
2. How do the probabilities of outcomes y change as a function of x in the logistic regression model? How does this limit the classification ability of Logistic regression?
3. Compare the decision boundaries of Gaussian Naive Bayes and Logistic Regression on the following data sets. Draw the Logistic Regression decision boundary with a solid line and the Gaussian Naïve Bayes Boundary with a dashed line. If one (or both) of the methods cannot classify the data, indicate this fact and write one sentence explaining why not.
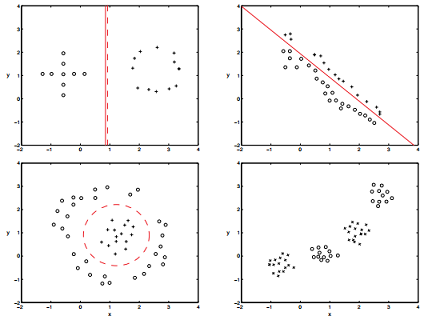
Q5. Learning theory
Assuming two classes and denoting the number of samples in each class as N and the dimension of the input space as D. Declare or compute the VC dimension of the following classifiers. State your assumptions and briefly justify your answers-use drawings if necessary.
1. A K-nearest neighbor classifier with K = 1.
2. A single-layer perceptron classifier.
3. Assume D = 2. A square that assigns points within as one class and points outside as another class. Draw a scenario where this classifier shatters all points for the VC dimension you have proposed.
Q6. Decision Trees
1. We are trying to classify individuals as Males (M) or Females (F) based on weight and height information. The tables below summarize the information we collected for training a model:
|
Weight
|
> 130
|
< = 130
|
|
M
|
45
|
5
|
|
F
|
30
|
10
|
|
Weight
|
> 150
|
< = 150
|
|
M
|
30
|
20
|
|
F
|
10
|
30
|
|
Height
|
> 5 feet
|
< = 5
|
|
M
|
50
|
0
|
|
F
|
30
|
10
|
|
Weight
|
> 6
|
< = 6
|
|
M
|
15
|
35
|
|
F
|
0
|
40
|
H(3/5) = 0.97
H(1/3) = 0.92
H(3/4) = 0.81
H(4/5) = 0.72
H(3/8) = 0.95
H(7/15) = 0.99
H(1) = 0
(a) Using these tables, construct two decision tress (one only using weight and other only using height). You may find some of the H values listed above useful for constructing these trees.
(b) What is the expected error of each of the trees you constructed?
(c) Is there a way to combine the two trees to classify a new input sample?
(d) Assume we have all the training data summarized in the tables above. We use this to construct a single tree that uses all the data (so basically we have, for each individual, 5 binary values: the label (M/F), whether their height is > 5, whether their height is > 6, whether their weight is > 130 and whether their weight is > 150). Select the most appropriate answer from below and briefly explain. When comparing this tree to the method you proposed in (c) using a test set the most likely outcome is:
i. The single tree would outperform the two trees approach.
ii. The two trees approach will outperform the single tree approach.
iii. Both methods would achieve similar results.
Q7. SVM
1. (True/False) When the data is not completely linearly separable, the linear SVM without slack variables returns w = 0.
2. (True/False) Assume we are using the primal non linearly separable version of the SVM optimization target function. What do we need to do to guarantee that the resulting model is linearly separable?
3. True/False After training a SVM, we can discard all examples which are not support vectors and can still classify new examples.
4. Show that if k1(x, x') and k2(x, x') are kernels, then k(x, x') = k1(x, x')k2(x, x') is also a kernel.
5. Consider a 2 class classification problem with a dataset of inputs {x1 = (-1, -1), x2 = (-1, +1), x3 = (+1, -1), x4 = (+1, +1)} and a corresponding set of targets {t1, t2, t3, t4} where ti ∈ {+1, -1}. Using this feature space (no kernel trick), can we build a SVM to perfectly classify this dataset regardless of values of ti's?
Q8. Neural networks
1. (True/False) Increasing the number of layers always decrease the classification error of test data.
2. We are trying to classify samples that only contain binary features. Can the following three classification algorithms be implemented using a feed-forward neural networks for such data, using units that are hard thresholds or linear activation functions? For each say yes / no. If yes, briefly explain how (no need to draw). If no, briefly explain why.
(a) Naive Bayes with binary features
(b) Decision Trees with binary features
(c) 1-NN
Q9. Hierarchical Clustering
1. Assume we are trying to cluster the points 20, 20, 21, 22, . . . , 2n (a total of n points where n = 2N) using hierarchical clustering. If we are using Euclidian distance, draw a sketch of the hierarchical clustering tree we would obtain for each of the linkage methods (single, complete and average)
Single link tree:
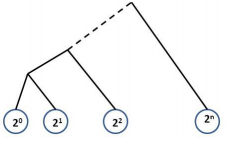
Complete link tree:
Average link tree:
2. Now assume we are using the following distance function: d(A, B) = max(A, B)/ min(A, B). Which of the linkage methods above will result in a different tree from the one obtained in (1) when using this distance function? If you think that one or more of these methods will result in a different tree, sketch the new tree as well.
(a) Single link
(b) Complete link
(c) Average link
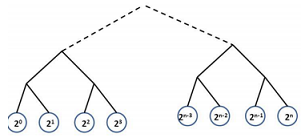
3. We would like to use a hierarchical clustering tree as a decision tree. We select a linkage method and build the tree from the training data. For a test sample, at each node in the tree we compute the distance between the test sample and the sub-cluster rooted at that node using the linkage method we selected. This way each test sample is propagated down the tree. Specify a linkage method that, when using such method, will lead to a hierarchical clustering decision tree that is exactly the same as a classifier we discussed in class. What is this classifier? Be specific.