Reference no: EM133115565
Data Mining for Business Analytics and Cyber Security
Task overview:
Exercise One
Question 1:
Present an example where data mining is crucial to the success of a business. What data mining functions does this business need? Can they be performed alternatively by data query processing or simple statistical analysis?
Question 2 :
Suppose your task as a software engineer at a University is to design a data mining system to examine their university course database, which contains the following information: the name, address, and status (e.g., undergraduate or postgraduate) of each student, the course taken, and their cumulative grade point average (GPA). Describe the architecture you would choose.
Question 3:
Describe a standard form of data to be acceptable in predictive data mining techniques.
Question 4:
Which type the following variables can be classified to:
a) National ratings of computer science departments.
b) Pulse rate in beats/minute.
c) Adult Status
d) Age in years.
e) Class - Freshman, Sophomore, Junior, Senior, Grad Student.
f) Colors
Exercise 2
1. What is the difference between classification and regression? How are they similar?
2. What is difference between supervised and unsupervised Learning with examples?
3. The following table contains training examples that help predict whether a patient is likely to have a heart attack.

1. Using the heuristic of "selecting the attribute based on that it will best separate the samples into individual classes" to construct a minimal decision tree that predicts whether or not a patient is likely to have a heart attack. Show each step.
2. Do you need all the attributes for constructing this minimal decision tree?
3. Translate your decision tree into a collection of decision rules.
Exercise 3
1. What is a Perceptron and what is Multilayer perceptron? Illustrate the structure of aperceptron and multilayer perceptron.
2. Given two objects represented by the tuples (22, 1, 42, 10) and (20, 0, 36, 8):
a) Compute the Euclidean distance between the two objects.
b) Compute the Manhattan distance between the two objects.
3. In the following dataset, 4 subjects belong to two different classes (A and B). Classify the new subject (Subject: Feature 1= 3; Feature 2=7; Class=?) using k nearest neighbour classification. Using Euclidean distance as distance function and the object is assigned to the majority class within the K nearest neighbour.
Perform kNN classification for the following values of k:
(a). k = 1
(b). k = 3
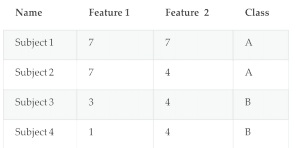
New Subject: Feature 1= 3; Feature 2=7; Class=?
Exercise 4
1. Compare the advantages and disadvantages of (a) K-means and (b) K-medoids for clustering.
Discuss a main challenge common to both the K-means and K-medoids algorithms.
2. Explain inter-cluster and intra-cluster distances and their relationship when used to evaluate clustering results?
3. Suppose that the data mining task is to cluster points (with (x, y) representing location) into three clusters, where the points are:
A1(2, 10), A2(2, 5), A3(8, 4), B1(5, 8), B2(7, 5), B3(6, 4), C1(1, 2), C2(4, 9).
The distance function is Euclidean distance. Suppose initially we assign A1, B1, and C1 as the center of each cluster, respectively. Use the k-means algorithm to show only
(a) the three cluster centers after the first round of execution.
(b) the final three clusters.
Exercise 5
Question 1.
a) Calculate the confidence of rules A → BCD, and ABC → D given their support?
b) Given a frequent itemset (ABCD), generate all the association rules with three items on LHS (Body) and one item on RHS (Head)?
Please note: Rule form: X (LHS or Body) → Y (RHS or Head)
LHS stands for Left hand side and RHS stands for Right hand side in the rule.
Question 2.
Consider an example of a supermarket database which might have several thousand items of which 1000 items are frequent and several million transactions. Which part of the Apriori algorithm will be most expensive to compute? Why?
Question 3.
Consider the market basket transactions shown in the following table. Assume that min_support = 40% and min_confidence = 70%. Further, assume that the Apriori algorithm is used to discover strong association rules among transaction items.
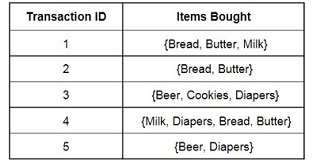
a) Show step by step the generated Candidate itemsets (Ck) and the qualified frequent itemsets (Lk) until the largest frequent itemsets are generated.
b) Generate all possible association rules from the frequent itemsets obtained in the previous question. Calculate the confidence of each rule and identify all the strong association rules.