Reference no: EM132400010
Problem 1: Classification of e-tailer customers (Real-world problem) using Support vector machines and Random forest. You can use weka or Scikit-learn python programming.
Objectives: E-commerce Customer Identification (Raw). Try to get the best performance using preprocessing, feature selection, data balancing, and parameter tuning.
The task involves binary classification to determine customers of the e-tailer. The training data contains 334 variables for a known set of 10000 customers and non-customers with a ratio of 1:10, respectively. The test data consists of a set of examples and is drawn from the same distribution as the training set.
Data: The feature data is train.csv and the label data is train_label.csv with corresponding labels for the records in train.csv. The test.csv is the test data.
Preprocessing steps to do:
You may use excel or write a simple script to merge the feature data file with label data file and save as csv file, then you can import into weka system.
Missing values: Check if there are any missing values inside the dataset, if so, use Weka's missing value estimation filter to estimate the missing values to make the data complete.
Normalization: since the features have very different value ranges, apply weka's normalization procedure to make them comparable.
Attribute/Feature selection: Since there are 334 features in the dataset, it may be useful to use some feature/attribute selection to reduce the dataset before training classifiers. Select one method (weka->filters->supervised->attribute->attributeSelection) to do feature selection. Describe your selected method and explain how it works briefly.
Hint 1: after you import the merged csv file into weka, the class label 1/0 is regarded as numeric value rather than nominal labels. You need to use the weka->filter->unsupervised->attribute->numeric2Nominal filter to convert that column to nominal class. (you need to specify which column is your class label to apply this conversion) Also note that weka take first line as feature names!! So need to add a line of feature names.
Hint 2: The dataset is a severely unbalanced dataset. You may want to balance the data before training the classifier.
Hint 3: if your training data has been applied a set of normalization or feature selection, you need to do the same with test dataset, otherwise the feature values are not consistent, and you will get absurd results on test data.
Hint 4: The best AUC value for this problem is 0.6821. See what u can get.
Experiments to do:
1) Experiments on the training dataset
You will need to build a classifier using a SVM and Random Forest algorithms to classify the data into customers and non-customers and evaluate their performance.
Pick one decision tree algorithm from Weka such as J48graft and describe it. (There are many decision tree algorithms)
Explain pre-processing filters in the table below. Run your decision tree algorithm with the default parameters. This is to learn how the preprocessing affects performance.
Write down the corresponding performance measures for class 1 (customer) in the following table for each processing.
All measures are based on 10-fold cross-validation results (except the last row). Put your results in Table 1 (below).
2) Use your best classifier you trained in step one, predict the class labels for the test dataset test10000.csv. Save your prediction labels into the predict.csv file.
Write a program to calculate precision, recall, MCC using the true labels in the test10000_label.csv and the predicted labels in your predict.csv file.
Table 1: Comparing performance of classifier on test dataset
|
Algorithm performance
|
Precision
|
Recall
|
MCC
|
ROC area
|
|
SVM (10-fold CV)
|
|
|
|
|
|
Random Forest (10-fold CV)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Result on test data
|
|
|
|
|
Report requirement:
1) Describe the preprocessing methods you used in the above experiments: missing value estimation, normalization, attribute selection, random forest.
2) Report the performance results in Table 1.
3) Submit the program to calculate the performance measures: Precision, Recall, MCC from two label files.
Problem 2: Regression using SVR (Support vector regression) or Random Forest
The problem here is to develop a regression model that can beat a theory model.
Attached thermal-data.xlsx contain a dataset for material thermal conductivity.
Develop two regression programs (one is SVR, the other can be RandomForest) to predict the thermal conductivity (y-exp) using the all the features before it. (V,M,n,np,B,G,E,v,H,B',G',ρ,vL,vS,va,Θe,γel,γes,γe,A,).
Report the MSE, RMSE, MAE, R2 of 10-fold cross-validation. Compare the MSE, RMSE, MAE, R2 of the theoretical model using the values in column y-theory.
Try to tune your parameters of the models to achieve the best performance.
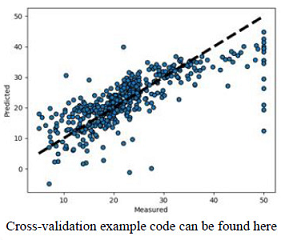
Plot the final scatter plot for your best model/result. The better the points are around the diagonal line the better your model is.
Attachment:- Assignment File.rar
Attachment:- Data Files.rar