Reference no: EM133285031
Problem 1: Variational Autoencoders
Consider the following two joint distributions:
qdata,Φ (x, z) = pdata(x)qΦ(z|x)
and
pη,θ(x,z) = pη,(z)pθ(x|z)
where pdata(x) is the data density and qΦ(z|x), and pθ (x |z) are are respectively the densities of the variational posterior, the latent variable, and the decoder with parameters Φ, η, and θ.
Question 1. Show that the KL divergence between qdata,Φ(x,z) and pη,θ(x,z) is
Epdata(x) )LVAE(x;Φ, η, θ)
where LVAE = DKL [qΦ(z|x)||Pη)(Z)] - EqΦ{z|x) is the negative cif the Evidence Lower Bound (ELBO).
Question 2. Next, consider the Fisher Divergence between two distributions qdata,Φ(x,z) and pη,θ(x,z) defined as
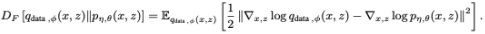
For any distribution p(x), define
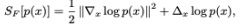
where ∇ and Δ respectively denote the gradient and the Laplacian operators. Show that
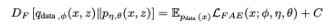
with
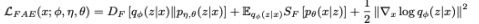
and C is a constant independent of Φ, η, and θ.
Problem 2: Slow Feature Analysis
Consider the following 4 signals:
x1(t) = cos(10t) - 1
x2(t) = sin2(5t) + sin(t/3)cos(2t/3) -1/2
x3(t) = sin(2t/3)oos(t/3)
x4(t) = sin(5t)
Question 1. In the provided Python notebook template, create IMO datapoints equally spaced by 3 in (0,10) from the aforementioned signals. Next, implement the function
fθ(t) = ∑i=14 ai xipi(t) + a0,
with θ = (a0, a1, a2, a3, a4, p1, p2, p3, p4), where p1, p2, p3, p4 ≥ 1, a1, a2, a3, a4 are real numbers not equal to zero, and a0 ∈ R.
2. implement gradient descent (from scratch) to minimize the following loss:
L(θ) = 1/999∑t=1998 ||fθ((t +1)δ) - fθ(tδ)||2
subject to the constraints
1/ 1000 ∑t=0999 fθ(δt) = 0
and
1/ 1000 ∑t=0999 fθ(δt)2 = 1
Plot t vs fθ(t), for 1000 equally-spaced values of t in [0,10).
Problem 3: Dictionary Learning with MCP and Group LASSO
In this problem, we will explore. sparse coding For the MNIST dataset Each MNIST image x is in R784x1 after flattening. From this, we define a dictionary D∈R784x100 where each column of the dictionary is dictionary element in R784x1 We also define the sparse representation of x to be h ∈ R100x1.
1. Initialize the dictionary D with torch. nn, . normal_ (tensor niean=0 . 0, std=1 CD, and normalize each column to have a norm of 1 by dividing each column with its min m Specifically, after initializing, for each column D[:, i], of the dictionary, normalize via D[:,i] = D[:, i]/||D:, i||2.
2. Implement code that solves for the sparse representation h(t), using each of the LASSO, MCP, and Group LASSO methods, by using gradient descent to minimize their following loss functions (LtAssea, Limo. and respectively). In class we gave the exact formulation for LASSO:
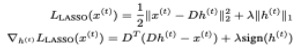
We provide the formulae for MCP and Group LASSO here!
MCP:
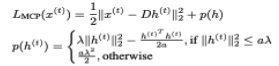
where a and λ are hyperparameters; We set a = 2, λ = 0,1 Next,
Group LASSO:
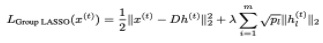
In Group LASSO, we separate h into m = 5. groups, i.e., h (h1, h2 ,h5).. Each hr for 1 ≤ t ≤ m represents a group of entries from h. The parameter pt represents the number of entries in the 2-Eh group hr_ in this problem, each group has the same number of entries, i.e.,. hi E E [1, (Separate entries of .h by order, i.e h1 includes the first 20 entries, h includes the following 20 entries, etc.)
3. Implement code that uses the projected gradient descent algorithm to solve for the update of dictionary D, given sparse representations Perform the update in three separate eases, using the sparse representations solved for in the previous part
4. Iterate Step 2 and Step 3 until convergence.
5. Plot the validation loss of training both the dictionary D and sparse representation h., with respect to epochs_ You should have six plots:
(a) validation loss 01D with LASSO,
(b) average validation loss of testing A's with LASSO,
(c) validation loss of D with MCP,
(d) average validation loss of testing ft's with MCP,
(e) validation loss of D with Group LASSO, (1) and average validation loss of testing it's with Group LASSO_
With a dictionary D ∈ R784x100 we learn 100 dictionary elements which are in R784x1. With each loss, we learn a different dictionary DLASSO, DGroup LASSO, and DMCP. Plot the first 10 dictionary elements learned with each loss(i..e., DLASSO[:, 0:9], DGroup LASSO[:, 0:9]) and DMCP[:., i], DGroup LASSO[:, i]. Specifically, reshape each of the first ten dictionary elements (DLASSO[:i] DGroup LASSO [:, i] and DMCP[:, i], ∈ {0, 1,...9}) to 28 x 28 and plot
(a) the first 10 dictionary elements. of DLASSO,
(b) the first 10 dictionary elements of DGroup, LASSO, and
(c) the irst 10 dictionary elements of DMCP
Attachment:- Term.rar