Reference no: EM133577555
Parallel Computing Lab Assignment
In this programming assignment, you will implement a parallel application with OpenMP and see yourself when it will will yield better performance than sequential version and when not.
You will write OpenMP program to determine the heat distribution in a space using synchronous iteration on a multicore. We have 2-dimensional square space and simple boundary conditions (edge points have fixed temperatures). The objective is to find the temperature distribution within. The temperature of the interior depends upon the temperatures around it. We find the temperature distribution by dividing the area into a fine mesh of points, hi,j. The temperature at an inside point is calculated as the average of the temperatures of the four neighboring points, as shown in the following figure.
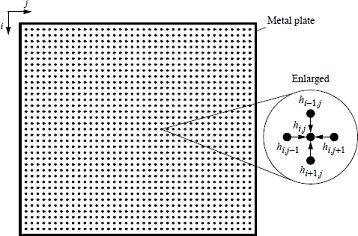
The edge points are when i = 0, i = n-1, j = 0, or j = n-1, and have fixed values corresponding to the fixed temperatures of the edges. The temperature at each interior point is calculated as:
hi,j = (hi-1,j + hi+1,j + hi,j-1 + hi,j+1)/ 4
(0 < i < n ; 0 < j < n, remember that edge points have fixed values)
Stopping condition: You stop after a fixed number of iterations.
Assume we have (n x n) points (including edge points), the initial situation is as follows:
The edge points: (0,0) à (0,n-1), (0,0)à(n-1,0), (0,n1-)à(n-1, n-1), and (n-1,0) à (n- 1,n-1) are initialized to 100. Note that (x,y) means row x and column y.
All other points are initialized to zero.
Remember that the boundary points do not change across iterations.
There will be a fixed number of iterations ITR. In each iteration, each point in the grid will be updated. But be careful: The points at iteration i must use the neighbors' values of iteration i, not the updated version. That is, if you are at iteration 10, for example, and you updated point (5,7). This point (5,7) is used to calculate the temperature of its neighbors. When updating the temperature of these neighbors, use the old value of (5,7) because its new value will be used in the following iteration. So, you may need to have a temporary storage for values of iteration i and you update the values in a different storage. Then, in the next iteration, the second storage becomes the new current and you update the other one.
As a help, we are providing you with a source code, heatdist.c, that contains the sequential code and the time measurement. You just need to plugin your code in that file as indicated in the comments in the file.
What you must do:
Read the file heatdist.c very carefully to understand how it works. Be careful that the 2D arrays are accessed as 1D array using the macro index(i,j,N). So, if you want to access array playground of dimension 100x100 (all arrays are assumed to be square) then playground[2,3] is accessed using playground[index(2, 3, 100)].
Do not change anything except the function parallel_heat_dist(). The code will take care of measuring the timing.
SSH to one of the crunchy machines
type: module load gcc-12.2
Compile the file, without any modifications from your part, first and make a run. The compilation command is: gcc -Wall -std=c99 -fopenmp -o heatdist heatdist.c -lm
You run the code with ./heatdist x y z k where x is the dimension of the 2D array, y is the number of iterations and z can be 0 (runs and measures the time of the sequential version) or 1 (run the OpenMP version when you finish it and measure the timing), and k is the number of threads for the OpenMP version. Note that even if you try with z = 0 (i.e. sequential version) you have to type a number for k. Otherwise, the program will exit.
Be careful: when you run your OpenMP version (i.e. z= 1) the code will take long time because it will run both the sequential and parallel in order to compare the results for correctness. It will measure the time of the parallel version only.
The report
Once you are done implementing your OpenMP version in file heatdist.c, do the following experiments.
Experiment 1
Fix the number of iterations to 100. For the 2D square array, test with sizes: 10, 100, 1000, and 20000. For each one of these sizes, get the time for the sequential as well as the parallel with four threads. Calculate the speedup, for each size of the four threads version relative to the sequential version. So, you need to have a table like the following where the second row is the speedup.
10 100 1000 20000
Then answer the following questions:
What is the pattern that you can see from the results in the table?
How do you interpret the results in that table?
Experiment 2
Fix the array dimension to 1000. The number of iterations varies as: 10, 20, 30, 40, and 50.
For each one calculate the speedup of four threads version relative to sequential and fill up a table like the following where the second row is the speedup.
10 20 30 40 50
Then answer the following questions:Is the speedup affected more with the number of iterations? or with bigger array size?Try to justify your finding in the above question.
What to submit:
The source code heatdist.c
A report that contains the graphs and answers to the questions mentioned above.