Reference no: EM131897689
Learning outcomes
The following learning outcomes will be assessed in TMA 02:
- to identify and understand relationships within the data
- to be able to design a quantitative research methodology to explore a finance research problem to conduct time series and cross-sections regression analyses
- to be able to identify relevant theories in the finance literature and to test hypotheses
- to be able to distinguish and choose amongst the range of methods available for the collection of evidence (data) and understand the characteristics of this evidence.
Introduction
In this TMA, you will practise hypothesis tests on single variables as well as the design of multiple regression models and associated hypothesis tests. The data for this TMA are based on the World Economic Outlook (WEO) and it is similar to what you saw in Session 4 of Unit 5. The quantitative data you will use in this TMA are located in the file B860_17K_TMA02_dataset.xlsx. Table 1 describes the variables contained in this file.
Table 1. Codes and descriptions of the variables in the dataset
Variable Code Description
PPPPGDPlog Gross domestic product based on purchasing-power-parity (PPP) per capita GDP (natural logarithm), in current international dollars; 2015
GFCF Average total investment as percentage of GDP; 2010-2015
GOV_EXP Average general government total expenditure as a percentage of GDP; 200-2015
TAXTOT Average Taxes on income, profits, and capital gains, percentage of total tax revenue 2004-2014 NETMR Average net migration rate per 1000 people, 2010-2015
REMIN Remittances inflows as percentage of GDP, 2015
DCBFS Domestic credit provided by financial sector as percentage of GDO, 2010-2015
TOTUN Total Unemployment as percentage of total labour force, 2015 FDINI Foreign direct investment, net inflows, 2015
INTU Internet users as percentage of total population, 2015
HDIAGR Average annual HDI (Human Development Index) growth, 1990-2015 INEQIN Inequality in income, 2015
SHSIT Share of seats in parliament held by women, 2015
AAPOPGR Average Annual Population growth (natural logarithm); 2010-2015
SPPSE Population with at least some secondary education, percentage ages 25 and older MRU5 Average mortality rate under 5 years per 1000 live births, 2010-2015
CC Country name as identification variable
CO The continent on which the country is located
Question 1
Descriptive statistics
Produce a table with the mean, median, minimum, maximum, standard deviation and skewness for the following variables in this dataset: PPPPGDPlog, GFCF, GOV_EXP, TAXTOT, and NETMR. One constraint applies to your calculation of the mean, standard deviation and skewness: You are not allowed to use the Data Analysis Toolpak in Excel or any of these functions: stdev.p, stdev.s, stdeva, stdevpa, stdev, stdevp, skew.
Question 2
Group differences
Compare GDP per capita (PPPPGDPlog) for three groupings of countries. Define three pairs of country groups as follows:
- Split by continent: European countries vs Asian countries.
- Split by name of the country: Countries beginning with letters A-L vs countries beginning with letters M-Z.
- Split by median of inequality in income (i.e. INEQIN): find the median of the variable and select all countries below and equal to the median in the first group and all countries above the median in the second group.
Do you expect a group difference for the mean logarithm of GDP per capita in these comparisons? Why or why not?
Apply an appropriate test to assess whether the mean logarithm of GDP per capita is different between the two groups in each of the above grouping.
Question 3
Interpretation of multiple regression
Table 2 shows the results for a regression of GDP per capita (log) on six variables at the country level.
Table 2. Regression of GDP per capita on country characteristics
SUMMARY OUTPUT
|
SUMMARY OUTPUT
Regression Statistics
Multiple R
|
0.7528
|
|
R Square
|
0.5667
|
|
Adjusted R Square
|
0.5352
|
|
Standard Error
|
0.8267
|
|
Observations
|
134
|
|
ANOVA
|
df
|
SS
|
MS
|
F
|
Significance F
|
|
Regression
|
9
|
110.8340
|
12.3149
|
18.0177
|
0.0000
|
|
Residual
|
124
|
84.7524
|
0.6835
|
|
|
|
Total
|
133
|
195.5864
|
|
|
|
|
|
Coefficients
|
Standard Error
|
t Stat
|
P-value
|
Lower 95%
|
Upper 95%
|
|
Intercept
|
7.5678
|
0.3812
|
19.8523
|
0.0000
|
6.8133
|
8.3224
|
|
GFCF
|
0.0000
|
0.0109
|
-0.0005
|
0.9996
|
-0.0216
|
0.0216
|
|
GOV_EXP
|
0.0183
|
0.0149
|
1.2258
|
0.2226
|
-0.0112
|
0.0478
|
|
TAXTOT
|
0.0252
|
0.0072
|
3.4883
|
0.0007
|
0.0109
|
0.0394
|
|
NETMR
|
0.0360
|
0.0099
|
3.6261
|
0.0004
|
0.0163
|
0.0556
|
|
DCBFS
|
0.0046
|
0.0015
|
3.1163
|
0.0023
|
0.0017
|
0.0075
|
|
TOTUN
|
-0.0167
|
0.0112
|
-1.4936
|
0.1378
|
-0.0389
|
0.0054
|
|
FDINI
|
-0.0035
|
0.0070
|
-0.4977
|
0.6196
|
-0.0175
|
0.0104
|
|
Europe
|
1.4054
|
0.2139
|
6.5716
|
0.0000
|
0.9821
|
1.8287
|
|
Asia
|
0.7087
|
0.1999
|
3.5457
|
0.0006
|
0.3131
|
1.1043
|
You are required to:
a. Write down the estimated equation for the model estimated in this regression.
b. Interpret the results also in terms of relationship between dependent and explanatory variables. Does the model explain GDP per capita? Which variables explain GDP per capita? Which do not?
c. Look at the graph below about the residuals versus fitted Y. For which assumption of the linear model is this graphical analysis used? Do you think that this regression output violates this specific assumption or not? Justify your answer.
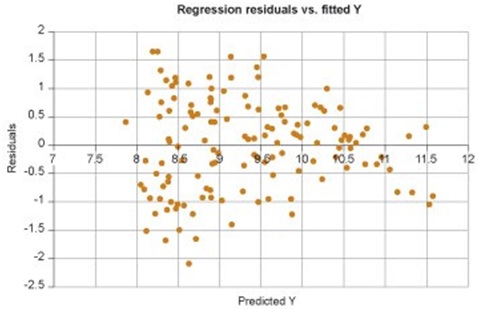
d. Find the countries with the largest positive and negative residuals from this regression (e.g., using the dataset in combination with the regression results). How can you interpret the large residuals shown by these two countries?
Question 4
Finding the best fit
a. Find the model that best explains GDP per capita (log) and which only uses explanatory variables that are significantly different from zero. Select variables from the dataset B860_17K_TMA02_dataset.xlsx as appropriate and justify the approach you take to arrive at the best model.
b. Explain whether you think the estimated coefficients in this model provide a recipe to increase a country's GDP per capita.
Attachment:- Dataset.rar