Reference no: EM132515508
Question 1. Filtering
Consider the 1D image below:

Part (a) Suppose we apply a width-3 mean filter TWICE to this image. In other words, we apply a width-3 mean filter to I to produce a smoothed image J, and then re-apply the same width-3 mean to J. Give the expression for J after both filters have been applied. Apply the filter only to valid image areas.
Part (b) Define a single 1D kernel that, when applied only once to the image, will produce the same results as applying the I.D width-3 mean filter twice.

Part (c) Convolutions are associative, meaning that if H1 and H2 are filters and F is an image, then
H1*(H2 * F) = (H1* H2)* F
Let's test this out with our mean filter example. Try applying a width-3 mean as shown described, to the mean filter image below and specify the result (give the center 5 pixels values). What effect will the repeated application of this filter have on an image?
(d) Suppose the size of an image is NxN, estimate the number of operations (an operation is an addition or multiplication of two numbers) saved if we apply the 1D filters g (d x 1) and h (1 x d) sequentially instead of applying the d x d 2D filter K. Express your answer in terms of N and d. Ignore the image boundary cases so you don't need to do special calculations for the pixels near the image boundary.
Question 2. Canny Edge Detection
Below you see a set of images. Image A is the original image while image B is obtained by adding some white noise to A. Three students are asked to apply the Canny edge detector on image B. The final results that they obtain are shown in images C, D, and E. Only one student answered the question correctly. Which image corresponds to the correct result? Explain for the other two images, what led to the wrong output and what needs to be done in order to get a good detection result. In your answer also state which "optimal" edge detection criteria do they not meet?

Fig. 1: Canny Edge Detection Results
Question 3. Feature Detection and Description
(a) We want a method for detecting corners in grayscale 3D images, i.e., there is an intensity value for each (x,y,z) voxel. Describe a generalization of the Harris corner detector by giving the main steps of an algorithm. What criteria would you use to find corners?
(b) The SIFT descriptor is a popular method for describing selected feature points based on local neighborhood properties so that they can be matched reliably across images. Assuming feature points have been previously detected using the SIFT feature detector, (1) briefly describe the main steps of creating the SIFT feature descriptor at a given feature point, and (ii) name three (3) scene or image changes that the SIFT descriptor is invariant to (i.e., relatively insensitive to).
Question 4. Lines
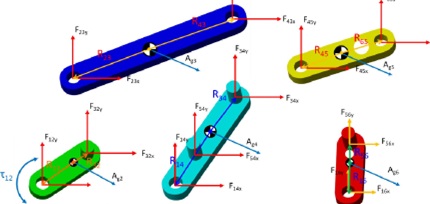
After running the Hough transform on the edge image on the left, you get the image on the right in the Hough domain as shown in Fig. 2. Explain the meaning behind these results.
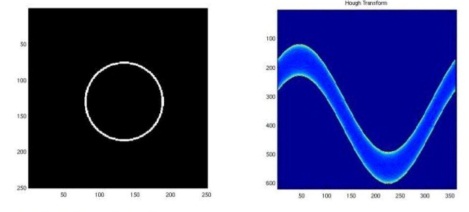
Fig. 2: Canny Edge Detection Results
Question 5. Optical Flow
(a) What is the difference between the optical flow field and the motion field? For the two optical flow fields shown in Fig. 3 describe a scene and a camera movement that could produce them.
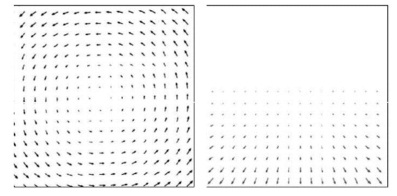
Fig. 3: Optical Flow Fields
(b) Can we reliably estimate the optical flow across all directions in an image? If not, what is that direction and what causes this?
Question 6. Depth-Stereo
(a) Consider the following top views of a stereo camera setup. What can you say about the epipoles and epipolar lines for each camera? Following your observations try to draw how the the epipoles and epipolar lines would look for each ca mera front view and clearly label their approximate positions.

(b) You are considering building a stereo video system for use in a flying vehicle. It will consist of two cameras, each having a ccd sensor with 512x512 photo detectors on a 1 cm2 sensor. The lenses have a focal length of 16mm. The x-axes of the two image planes are parallel to the epipolar lines. The baseline between the cameras is 0.3 m. If the nearest range to be measured is 5 meters, what is the largest disparity that will occur (in pixels)?
Question 7. Clustering

Describe how you would use the K-means method to compress an RGB image of 100 x 100 pixels. After you apply K-means to an image, you get the results in Fig. 4. What can you say about the best choice for the number of clusters? What is the compression rate achieved by your selected best choice of clustering?
Question 8. Machine Learning and Recognition
(a) You are working for a special effects company and want to have real actors inserted into a computer-generated world. One way to do this is to film the actors in front of a blue screen, so that the background can easily be segmented and substituted with a computer generated one. Due to lighting variations, the background will not appear pure blue, so checking for a single intensity value might not work well. Instead, you decide to model the distribution of background colors as a probability function. You are given a training image T with pixels labeled as foreground (F) and background (B). Define the following probability functions P(8) and Pc I B) based on T. Let P(B) denote the probability that a particular pixel is a background pixel, regardless of its color or position in the image. Let Pc I B) denote the probability that a background pixel has color c. In your functions, you can refer to properties of the image T like "number of pixels labeled as foreground in T".
(b) Suppose that you trained an algorithm for detecting people, chairs and airplanes. You obtained accuracies of 50%, 40%, and 80% on the 3 classes. State two possible reasons that can lead to such a behavior.
(c) You have designed an algorithm for classifying if the image contains a person or not. You obtain an accuracy of 98% on the training set and 33% on the validation set. State two possible reasons that can lead to such a behavior.
(d) The Viola-Jones algorithm was a breakthrough in terms of real-time face detection. Explain how the concept of integral image is used within the Viola-Jones framework to speedup the computation. With respect to that, what would be the difference if we change the weak learners from Haar features to some sort of convolutional features? In what way if any will this change affect the cascade structure?
(e) Given the table below. Which points are the support vectors and why? What factors can lead to a change of the support vectors? Find the weight vector w and bias b assuming linear SVM.

Question 9. Neural Networks
(a) If you are using a neural network, how can you modify it to improve performance on the validation set?
{b} When training a neural network what problem{s} will result from using a learning rate that's too low? How would you detect such problems?
(c) Consider the following neural network:
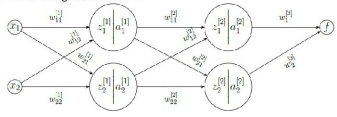
Fig. 5: Neural Network Graph
With zj[i] = ∑2k=1 wijk.xi and aj[i] = relu(zj[i]), where i is the layer index, and j is the per layer neuron index, and k is the weight index per neuron.
Given that f (x) = w1[3]a1[2] + w2[3]a2[2] compute: the full expression for updating the weights w11[1] and w21[1] assuming the weight rule: w' = w - a∂f(x)/∂w
(d) The Figure below demonstrates the results of two different optimization algorithms used to train a neural network. For each of the two explain if batch gradient descent was used or mini-batch gradient descent. Does the learning rate seem to be good enough? At which point you might try to decrease it?

Fig. 6: Learning curves for two training runs.
Question 10. Deep Learning
(a) What are some advantages of Convolutional Neural Networks over traditional fully connected neural networks with regards to Computer Vision. Give a practical example where these can be observed.
(b) What is the role of pooling in a CNN, how does it work, and why do we need it?
(c) The universal approximation theorem means that we can approximate functions arbitrarily well with 1 hidden layer. State a reason and explain why, in practice, you would use deeper networks.
(d) In this question, you will design a convolutional network to detect vertical boundaries in handwritten digit images. The architecture of the network is shown in Fig. 7. The ReLU activation function is applied to the first convolution layer while the output layer uses the linear activation function. We use white to denote 0 and darker values to denote larger (more positive) values.
a. Design two convolution kernels (w1 and w2) for the first layer, of size 3 x 3. One of them should detect dark/light boundaries, and the other should detect light/dark boundaries. (It doesn't matter which is which.). Briefly explain your reasoning.
b. Design convolution kernels (w3 and w4) of size 3x3 for the output layer, which computes the desired output. Briefly explain your reasoning.
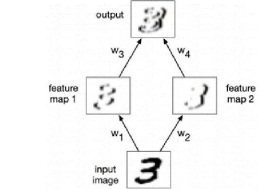
Fig. 7: Convolutional Neural Network
Question 11. General Questions
For each of the following, explain how it may be used to help solve a computer vision problem (and specify the problem).
(a) Principal components
(b) Sum-of-squared distances (SSD)
(c) Image Pyramid