Reference no: EM132371413
Data Science Assignment -
Question 1 - Classify the following attributes as binary, discrete, or continuous. Also classify them as qualitative (nominal or ordinal) or quantitative (interval or ratio). Some cases may have more than one interpretation, so briefly indicate your reasoning if you think there may be some ambiguity.
Example: Age in years. Answer: Discrete, quantitative (ratio)
1. House numbers assigned for a given street
2. Your calorie intake per day
3. Shape of a geometric objects commonly found in geometry classes.
4. Coat check number. (When you attend an event, you can often give your coat to someone who, in turn, gives you a number that you can use to claim your coat when you leave.)
5. Longitude and Latitude of a location on earth.
Question 2 - Below is an example of customer transaction database. Each row is the purchased items (binary variable, 1 for purchased, 0 or empty for not purchased) by one customer. Assume there are millions of items.
|
Items
|
Item 1
|
Item 2
|
Item 3
|
Item 4
|
Item 5
|
Item 6
|
Item 7
|
Item 8
|
Item 9
|
Item 10
|
|
Customer 1
|
1
|
|
1
|
|
|
|
|
|
|
|
|
Customer 2
|
1
|
1
|
1
|
|
|
|
|
|
|
|
|
Customer 3
|
|
|
|
|
|
1
|
|
|
|
|
|
...
|
...
|
|
|
|
|
|
|
|
|
|
(1) Consider each row (customer purchased history) as a sample, and different columns as attributes. Are the binary attribute symmetric or asymmetric? Why?
(2) Compute similarity between Customer 1 and Customer 2, as well as similarity between customer 1 and customer 3. Use Simple Matching Coefficient and Jaccard Coefficient respectively.
SMC(1, 2) = ?
SMC(1,3) = ?
JC(1,2)=?
JC(1,3)=?
Which measure among the two better reflects customer similarity? Why?
(3) Assume the values in the table are not binary (purchased or not), but counts (non-negative integer) of items being purchased by a customer. Our goal is to recommend items to customers. In other words, we want to recommend an item that have not been purchased by a customer yet. Specifically, we will predict "the count of an item being purchased by a customer A" based on the average count of the same item being purchased by "the five most similar customers to A".
How would you measure similarity between customers in this case? Which measure would you prefer among SMC, Jaccard, Euclidean distance, Correlation, and Cosine? Why do you select this measure but not the others?
Question 3 - Assume sample p = (1,0,1,0,1,0), sample q = (3,-3,3,-3,3,-3). Answer the questions below:
(1) What are similarities between p and q based on "Cosine" and "Pearson's Correlation"?
Cosine(p,q)=?
Correlation(p,q)=?
(2) Assume we add all attribute in q by a constant 3, now q'=(6,0,6,0,6,0).
Cosine(p,q')=?
Correlation(p,q')=?
What did you find out by comparing results in (1) and (2)?
(3) Assume we multiple all attribute in q by 3, now q''=(9,-9,9,-9,9,-9).
Cosine(p,q'')=?
Correlation(p,q'')=?
What did you find out by comparing results in (1) and (3)?
Question 4 - Consider the dataset shown in Table 1.1 for a binary classification problem.
|
Customer ID
|
Housing Type
|
Gender
|
Marital Status
|
Class
|
|
1
|
Apartment
|
Male
|
Married
|
C0
|
|
2
|
House
|
Male
|
Single
|
C1
|
|
3
|
House
|
Female
|
Married
|
C1
|
|
4
|
Apartment
|
Female
|
Single
|
C0
|
|
5
|
Apartment
|
Male
|
Married
|
C0
|
|
6
|
Hostel
|
Male
|
Single
|
C1
|
|
7
|
House
|
Female
|
Married
|
C1
|
|
8
|
Apartment
|
Female
|
Single
|
C0
|
|
9
|
Apartment
|
Male
|
Married
|
C0
|
|
10
|
House
|
Male
|
Single
|
C1
|
|
11
|
Hostel
|
Female
|
Married
|
C1
|
|
12
|
House
|
Female
|
Single
|
C0
|
|
13
|
House
|
Male
|
Married
|
C0
|
|
14
|
Hostel
|
Male
|
Single
|
C1
|
|
15
|
Hostel
|
Female
|
Married
|
C1
|
|
16
|
Apartment
|
Female
|
Single
|
C0
|
a. Compute the entropy for the overall data.
b. Compute the entropy obtained for each of the four attributes (consider a multi-way split using each unique value of an attribute).
c. Compute the Information Gain (IG) obtained by splitting the overall data using each of the four attributes. Which attribute provides the highest IG, and which attribute provides the lowest IG.
d. For splitting at the root node, would you choose the attribute that provides the maximum IG? Briefly explain your choice.
f. Consider the following 3 decision trees:
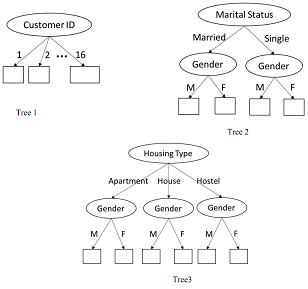
Compute the difference between the entropy of overall data with the weighted entropy of the leaves for each of the three trees. Based on these differences, which tree would you choose for performing classification? Is the attribute chosen at the root of this tree same as the attribute chosen for splitting in (e)? Briefly comment on the nature of your results, and the properties of the impurity measure used while constructing decision trees.
Question 5 - Consider a data set with instances belonging to one of two classes - positive(+) and negative(-). A classifier was built using a training set consisting of equal number of positive and negative instances. Among the training instances, the classifier has an accuracy m on the positive class and an accuracy of n on the negative class.
The trained classifier is now tested on two data sets. Both have similar data characteristics as the training set. The first data set has 1000 positive and 1000 negative instances. The second data set has 100 positive and 1000 negative instances.
A. Draw the expected confusion matrix summarizing the expected classifier performance on the two data sets.
B. What is the accuracy of the classifier on the training set? Compute the precision, TPR and FPR for the two test data sets using the confusion matrix from part A. Also report the accuracy of the classifier on both data sets.
C. i). If the skew in the test data - the ratio of the number of positive instances to the number of negative instances, is 1:s, what is the accuracy of the algorithm on this data set? Express your answer in terms of s, m, n.
ii). What value does the overall accuracy approach to if s is very large (>>1)? And when s is very small (<<1)?
D. In the scenario where the class imbalance is pretty high (say, s>500 for part C), how are precision and recall better metrics in comparison to overall accuracy? What information does precision capture that recall doesn't?
Question 6 - Below is the learning curve of a classifier ("classification accuracy on test set" versus "the number of training samples"). Please mark out which ranges of x-axis corresponding to "underfitting" and "overfitting" respectively. If you answer that the curve does not show "underfitting" or "overfitting", please explain why.
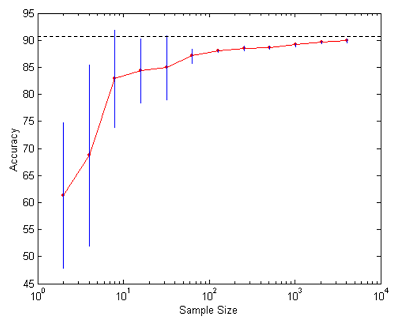
Question 7 - In each of the classification scenarios listed below, you are given a set of classifiers and a description of the classification scenario. For each scenario, state the choice of the classifier that is best suited for the dataset along with a brief explanation supporting your answer.
(a) Many of the attributes are irrelevant (contain no information about the class). Classifiers available: KNN, ANN, Decision Trees.
(b) Dataset contains attributes that are not discriminative by themselves, but are discriminative in combination. Classifiers available: KNN, Naïve Bayes, Decision Trees (taking single attribute at a time in a tree node).
Question 8 - Please prove a conclusion related to PCA we discussed in the class: the unit vector to which the projected sample points have the largest variance is the first eigenvector of sample covariance matrix. Please provide brief and sufficient mathematical inductions.
Question 9 - Logistic regression classifier directly models P(x_i|y_i), while naïve Bayes classifier model P(x_i,y_i) together. This is why logistic regression classifier is called "discriminative" and naïve bayes classifier is called "generative".
(1) Please write down the mathematics of model learning and prediction in logistic regression and naïve Bayes respectively. Assume a binary logistic regression classifier. You can also assume x_i follow conditional Gaussian distribution in Naïve Bayes. Use the maximum likelihood method for parameter learning in both models.
(2) Does the learning process of Logistic Regression involve a close-form solution (a direct math formula to compute learned parameters)? Why? If not, what are the strategies to learn parameter fast? Write down detailed math in your answer.
Question 10 - Prove that as the number of iterations increase to infinite, the expected loss of Adaboost is decreasing towards 0.