Reference no: EM133028053
Question 1 A 2-processor system uses the Illinois (MESI) cache coherency protocol, and is powered-on with its caches initially empty. Each processor has enough local cache to fit the variables B and C simultaneously. The bus operation BusRdX requires 3 bytes of bus transfer, whereas all others require 16 bytes. After completing the following sequence of actions, give the total number of bytes transferred for each bus operation.
a. P1 loads variable B.
b. P2 loads variable C.
c. P1 loads variable C.
d. P2 modifies variable C.
e. P1 modifies variable B.
Question 2 For a machine with the communication overhead and network delay (message start-up time) of 200 ns and the asymptotic peak bandwidth of 5 GB/s, calculate the communication time as a function of the number of bytes sent n.
Considering a program that runs 100 times an operation sending each time 2.5MB, assuming that 10% of operation communication time is during other useful work of processor, calculate the communication cost.
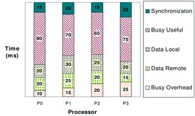
Question 3 An uniprocessor application is parallelized for 4 processors, yielding a 3.8x speedup. Given the time breakdown of the various functions seen in the graph, what is the minimum total time that the uniprocessor application spent while Busy and in performing Data Access?
Question 4 a) What is the difference between a write-through cache and a write-back cache? Why does using write-through caches in a shared memory multiprocessor not scale well to a large number of processors?
b) An alternative to the snooping cache coherence protocol is a directory-based scheme by which a table is maintained that shows where in the system is each cache line. Describe briefly the advantages and disadvantages of each system.
Question 5 Express a Test&Set instruction using LL and SC instruction using a pseudo-assembler code.
Question 6 Consider a bus-based shared memory multiprocessor system with write-through caches. It is constructed using 1.6 GHz processors, and a bus with a peak band- width of 50 Mega fetches/s. The caches are designed to support a hit rate of 90%. Only 15 % of program execution time is related to Read and Write commands. Assuming that each Read/Write instruction takes 2 clock cycles on average, what is the maximum number of processors that can be supported by this system?
Question 7 A uniprocessor application is parallelized for 3 processors, with time breakdowns of various functions seen in the table below. Find the maximum total speedup that is achieved through the parallelization.
Question 8 Given the following code segments, what results are possible (or not possible) under sequential consistency for cases a and b below? Assume that all variables are initialized to 0 before this code is reached.
c. In the following sequence, first consider the operations within a dashed box to be part of the same instruction, say a fetch&increment. Then, suppose they are separate instructions. Answer the above questions for both cases.
Question 9 The figure below shows network transactions assuming the simple directory based cache coherency protocoL
a) Use this figure to produce the sequence of events in a generic write-through invalidate directory-based machine for a write operation by a processor i, in the case when the dirty bit is ON.
b) Describe what happens with all the required transactions when considering the update protocol.
Question 10. Consider a bus-based shared memory multiprocessor system with write-back caches using the basic MSI cache coherence protocoL It is constructed using 1.6 GHz processors, and a bus with a peak band- width of 50 Mega fetches/s. The caches are designed to support a hit rate of 90%. Only 15 % of program execution time is related to Read and Write commands, and 5% cache operations result in writebacks. Assuming that each Read/Write instruction takes 2 clock cycles on average, what is the maximum number of processors that can be supported by this system?