Case study: A spider:
One of the most useful internet utilities is known as a spider. A typical spider roams around the World Wide Web examining pages and returning with information about those pages. This case study is concerned with developing a simple spider that visits a specified collection of web pages and determines whether particular content can be found on those pages. It produces a report that details those pages that contain the content.
The particular spider we shall build will examine a database that contains a list of web page addresses and regular expressions, and check whether substrings described by the regular expressions are contained in the pages.
The database that we shall use to contain page details and regular expressions will be defined by the Properties class. This is a file-based data structure whose class definition can be found in java.util. It is similar in concept to the HashMap class that you have met before in the course.
I have chosen to use a Properties object because it implements a map with keys and values, which are both strings (this fits our URLs and regular expressions perfectly), and because it is simple to save a Properties file and retrieve it later.
The contents of a typical Properties file are shown below:
David+Robson=HeadOffice Robert+Key=Accounts William+Masterton=Marketing
...
What we have is the file equivalent of a HashMap object. The string to the left of the = symbol represents the key (in the example above this is the name of an employee) and the string to the right of the = symbol is the value associated with the key (in the example above this is the department in which they work). Note that in Properties objects the space symbol is represented by the plus sign.
Properties objects are normally used to contain the parameters necessary for the running of a program. For example, they might be used to contain information about whether a program starts in beginner, intermediate or advanced mode by having a line such as:
Startupmode=advanced
within the Properties file.
Properties objects share many methods with HashMap objects. For example, you can send a get message to a Properties object in order to retrieve the value associated with a particular key.
Within the spider application that we are going to develop, the Properties object used will contain the URLs of web pages as the keys and the regular expressions that should be used to search the web pages as the values. For example, the Properties object might contain a line such as:
https://bbc.co.uk=Fine*last
which would indicate that the BBC home page should be searched for a string consisting of "Fin" followed by any number of e characters (including zero) and then the string "last".
The aim of the program that I describe is to process a Properties file with lines such as the one above and then produce a web page that states whether it contains the string described by the regular expression. The report on whether the pattern occurs will be displayed as an HTML file. For example, consider the following HTML file which contains the title "Search report" and a table declaration <TABLE></TABLE>. The table will have a width of 50% of the web page that it is displayed on and a border of one pixel.
<HTML>
<HEAD>
<TITLE> Search report</TITLE>
</HEAD>
<BODY>
<TABLE width="50%" border="1">
<TR>
<TD width="72%"><B>URL</B>
</TD>
<TD width="28%"><B>Pattern</B>
</TD>
</TR>
<TR>
<TD width="72%">news.bbc.co.uk/sport1/hi/cricket/counties/
glamorgan/4254329.stm
</TD>
<TD width="28%">Glamorg*n
</TD>
</TR>
<TR>
<TD width="72%">news.bbc.co.uk/1/hi/wales/mid/4254263.stm
</TD>
<TD width="28%">H*y
</TD>
</TR>
</TABLE>
</BODY>
</HTML>
Figure: shows an example of this table. It contains rows that include the URL of the file that is found, followed by the pattern that is matched. It is worth repeating that such a file will be dynamically generated by the program that I am going to describe in this first case study.
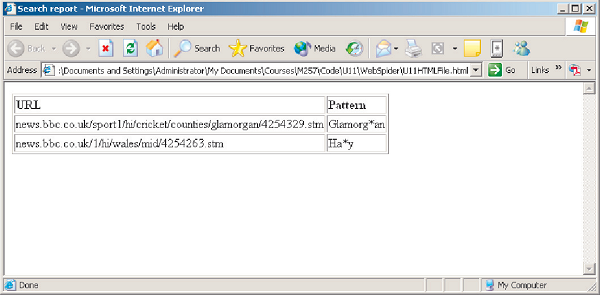
Figure: An example of the HTML page produced by the first case study
The file contains a heading for the table, which is described by the following HTML:
<TR>
<TD width="72%"><B>URL</B>
</TD>
<TD width="28%"><B>Pattern</B>
</TD>
</TR>
This shows the table as having two columns. The first column contains the word "URL" in bold (delineated by the HTML tags <B>...</B>) and the second column is headed by the word "Pattern", again in bold. The first column will span 72% of the width of the table, while the second column will span 28% of the table.
Following the table heading are two rows of the table. This is specified by the following
HTML:
<TR>
<TD width="72%">news.bbc.co.uk/sport1/hi/cricket/counties/
glamorgan/4254329.stm
</TD>
<TD width="28%">Glamorg*
</TD>
</TR>
<TR>
<TD width="72%">news.bbc.co.uk/1/hi/wales/mid/4254263.stm
</TD>
<TD width="28%">Ha*y
</TD>
</TR>
Here the first row contains in its first column the address of the page: news.bbc.co.uk/sport1/hi/cricket/counties/glamorgan/4254329.stm and the regular expression pattern that was discovered on it, "Glamorg*an", while the
second row contains the address:
news.bbc.co.uk/1/hi/wales/mid/4254263.stm
and the regular expression that was discovered, "Ha*y" (it detected Hay, a small and rather pretty town in east mid-Wales). Note that for simplicity I am assuming that the occurrence of only a single row indicates that one or more occurrences of the regular expression could occur on the web page, although the program will detect only the first.
The skeleton I shall use for the program that processes the Properties object and produces the HTML file is shown below:
import java.util.*; import java.io.*; import java.net.*;
import org.apache.regexp.*;
public class SearchDetails
{
private Properties propFile;
private String HTMLFileName;
...
}
Here a number of import statements are used: java.util is used for the Properties class, java.io is used for the various streams needed to communicate with the web pages found in the Properties file, java.net is used for classes that reference the web page, and org.apache.regexp is used to import the Apache regular expression library. The class has two instance variables: the Properties object containing the URLs and the regular expressions is propFile, and the object that references the HTML file that contains the report is HTMLFilename.
The constructor for the class is:
public SearchDetails(Properties propFile, String HTMLFileName)
{
this.propFile=propFile;
this.HTMLFileName=HTMLFileName;
}
All this does is initialize the two instance variables.
The bulk of the processing is carried out within a method called createReport. The first task of this method is to create the HTML file and write the header parts of the file. This is shown below:
System.out.println("Processing started");
//Create the file to hold the HTML code
PrintWriter HTMLFile=null;
try
{
HTMLFile =
new PrintWriter(new FileOutputStream(HTMLFileName),true);
}
catch(Exception e)
{
System.out.println("HTML file unable to be created");
}
//Write headers to the HTML file
HTMLFile.println("<HTML>");
HTMLFile.println("<HEAD>");
HTMLFile.println("<TITLE> Search report</TITLE>");
HTMLFile.println("</HEAD>"); HTMLFile.println("<BODY>");
The code creates a PrintWriter object that will clear its print buffer after every write statement is executed (the reason for having true as the second argument in the creation of the FileOutputStream object). In the very unlikely event of the file not being able to be created, an exception is created. After the HTML file is created, a series of HTML statements are written to the file. These statements are just the heading
statements for any HTML file.
String uRLValue =""; //A URL found in the Properties file
String regExps = ""; //A regular expression found //in the Properties file
URLConnection connect = null; //Used for establishing //a connection
InputStream is = null; //Next two lines used for //establishing a reader
BufferedReader bReader = null;
String lineRead=""; //Used to hold each line of //input from a web page
String searchString=null; //The string that is to be //searched, i.e. the web page
RE searchPattern = null; //The search pattern //(regular expression)
boolean countFound=false; //Have there been any matches
The variables uRLValue and regExps are used to hold the URL and the regular expression from each line of the Properties object. The variable connect is used to connect to a web page; later I shall show you how it is used. The variables is and bReader are used to process a single line at a time from the web page that is currently being examined. The variable lineRead is a string used to contain each line of the web page that is being examined. The string variable searchString is the string to be searched for that matches to a regular expression; this variable will hold the contents of the web page being examined. The variable searchPattern holds the regular expression that is to be used for a search and the boolean variable countFound is true if a search has been successful.
The next section of processing involves setting up the header of the HTML table that is to be generated; this is shown below:
String HTMLtable = "<TABLE width=\"50%\" border=\"1\">\n"+
"<TR>"+
"<TD width=\"72%\"><B>URL</B></TD>"+
"<TD width=\"28%\"><B>Pattern</B></TD>"+
"</TR>\n";
Here the string HTMLTable is created with the header information in it. Notice the use of the forward slash character to identify double inverted quotation marks, as in \"50%\" where the forward slash indicates that the quotation mark after it is to be printed.
The major processing that is carried out within createReport is to sequentially examine each line of the Properties object, extract out the URL of the web page that is to be examined and then extract out the regular expression that is to be used for searching. A connection to the web page is then established and a string formed from the page. This string is then searched for any substrings that match the regular expression. If a string is found then a line of HTML for the table is formed. The processing completes when the last line of the Properties object has been processed.
The code for the processing is shown below:
try
{
for(Object key: propFile.keySet())
{
//Get the key and the regular expression
//for each line in the Properties file
uRLValue = (String)key;
regExps = propFile.getProperty(uRLValue);
//Now get the contents of the page that
//has been identified
//First form a URLConnection
connect = (URLConnection)new
URL("https://"+uRLValue).openConnection();
//Now assign a reader
is = connect.getInputStream();
bReader = new BufferedReader URL.openStream is used to get an input stream. We (new InputStreamReader(is)); use as an alternative the searchString=""; method //Get the contents of the page and place getInputStream.
//each line in searchString lineRead=""; while(lineRead!=null)
{
lineRead = bReader.readLine();
searchString+=lineRead;
}
//Check whether the string is found in the page
//First create the regular expression that is to
//be searched for
searchPattern = new RE(regExps);
if(searchPattern.match(searchString))
{
//Search string has been found
//Issue a line of the table
HTMLtable+=("<TR><TD width=\"72%\">"+uRLValue
+"</TD><TD width=\"28%\">"
+regExps+"</TD></TR>\n");
countFound=true;
}
}
}
catch(Exception e)
{
System.out.println("Problem setting URL "+e);
}
The loop terminates when the Properties object has no elements.
The first task in the loop that processes each line of the Properties object is to extract out the URL and the regular expression. This is shown below:
uRLValue = (String)key;
regExps = propFile.getProperty(uRLValue);
Here the first line casts the key and the second line then uses this key to extract out the regular expression associated with the key.
The next stage in the processing is to connect to the web page described by uRLValue. This is shown below:
connect = (URLConnection)new URL("https://"+uRLValue)
openConnection();
This uses the class URL and the method openConnection to establish a URLConnection object that represents a connection to the web page. The method openConnection delivers an object described by Object and hence casting has to be used to get a URLConnection.
The next stage in the processing is to construct a Reader object that can read strings from the web page. The Reader object is a BufferedReader. This allows us to read single lines of text from the page.
is = connect.getInputStream();
bReader = new BufferedReader(new InputStreamReader(is));
Here the method getInputStream gets the input stream associated with the URLConnection object connect and the BufferedReader object bReader is then constructed from that stream.
Once a BufferedReader object has been formed, the lines making up the web page can be sequentially read. The first part of this processing is shown below:
searchString=""; lineRead=""; while(lineRead!=null)
{
lineRead = bReader.readLine();
searchString+=lineRead;
}
Here each line is read and added to the String object searchString. The processing finishes when the last line of the web page has been read:
(lineRead!=null)
The processing continues by forming an RE object that represents the regular expression to be searched for and then searching the string that represents the web page. If a string described by the RE object is found then a line of the table is added to the string HTMLTable and the boolean countFound adjusted.
searchPattern = new RE(regExps);
if(searchPattern.match(searchString))
{
HTMLtable+=("<TR><TD width=\"72%\">"+uRLValue
+"</TD><TD width=\"28%\">"+regExps+"</TD></TR>\n");
countFound=true;
}
The HTML string in the fourth and fifth lines above just writes the value of the URL of the web page and the regular expression associated with that page.
The final processing adds the terminating HTML statements to the HTML file, closes down the HTML file and issues a message that processing has finished. If no patterns were matched the table is not formed and a simple message is placed in the HTML file informing the user.
HTMLtable+="</TABLE>";
if(countFound)
HTMLFile.println(HTMLtable);
else
HTMLFile.println("No patterns were matched");
HTMLFile.println("</BODY>"); HTMLFile.println("</HTML>"); HTMLFile.close(); System.out.println("Processing finished");
The whole code for the class together with comments is shown below:
import java.util.*; import java.io.*; import java.net.*;
import org.apache.regexp.*;
public class SearchDetails
{
private Properties propFile;
private String HTMLFileName;
public SearchDetails(Properties propFile, String HTMLFileName)
{
this.propFile=propFile;
this.HTMLFileName= HTMLFileName;
}
public void createReport()
{
System.out.println("Processing started");
//Create the file to hold the HTML code
PrintWriter HTMLFile=null;
try
{
HTMLFile = new PrintWriter(new FileOutputStream(HTMLFileName),true);
}
catch(Exception e)
{
System.out.println("HTML file unable to be created");
}
//Write headers to the HTML file
HTMLFile.println("<HTML>");
HTMLFile.println("<HEAD>");
HTMLFile.println("<TITLE> Search report</TITLE>");
HTMLFile.println("</HEAD>");
HTMLFile.println("<BODY>");
String uRLValue ="";
//A URL found in the
//Properties file
String regExps = "";
//A regular expression found
//in the Properties file
URLConnection connect = null;
//Used for establishing
//a connection
InputStream is = null;
//Next two lines used for
//establishing a reader
BufferedReader bReader = null;
String lineRead="";
//Used to hold each line
//of input from a web page
String searchString=null;
//The string that is to be
//searched, i.e. the web page
RE searchPattern = null;
//The search pattern
//(regular expression)
boolean countFound=false;
//Count of the number
//of matches
//Set up the table header
String HTMLtable = "<TABLE width=\"50%\" border=\"1\">\n"+
"<TR>"+
"<TD width=\"72%\"><B>URL</B></TD>"+
"<TD width=\"28%\"><B>Pattern</B></TD>"+
"</TR>\n";
//Process the properties file line by line.
try
{
for(Object key: propFile.keySet())
{
//Get the key and the list of regular expressions
//for each line in the Properties file
uRLValue = (String)key;
regExps = propFile.getProperty(uRLValue);
//Now get the contents of the page that has been identified
//First form a URLConnection
connect = (URLConnection)new
URL("https://"+uRLValue).openConnection();
//Now assign a reader
is = connect.getInputStream();
bReader = new BufferedReader(new InputStreamReader(is));
searchString="";
//Get the contents of the page and place
//each line in searchString lineRead=""; while(lineRead!=null)
{
lineRead = bReader.readLine();
searchString+=lineRead;
}
//Check whether the string is found in the page
//First create the regular expression that is to
//be searched for
searchPattern = new RE(regExps); System.out.println(uRLValue+" = "+
regExps+ "\n"+searchString);
if(searchPattern.match(searchString))
{
//Search string has been found
//Issue a line of the table
HTMLtable+=("<TR><TD width=\"72%\">"+ uRLValue+"</TD><TD width=\"28%\">"+ regExps+"</TD></TR>\n");
countFound=true;
}
}
}
catch(Exception e)
{
System.out.println("Problem setting URL "+e);
}
//Write footers to HTML file and then close it
HTMLtable+="</TABLE>";
//Add table to file if at least one match is found
//If not send a simple message that no patterns were matched if(countFound)
HTMLFile.println(HTMLtable);
else
HTMLFile.println("No patterns were matched"); HTMLFile.println("</BODY>"); HTMLFile.println("</HTML>");
HTMLFile.close();
System.out.println("Processing finished");
}
}
The only code left to describe is the main method that carries out the execution. This is shown below:
import java.util.Properties;
import java.io.*;
public class Tester
{
public static void main(String[] args)
{
Properties pageFile = new Properties();
try
{
String pageDetails = ".." ;
File propsFile = new File(pageDetails);
pageFile.load(new FileInputStream(propsFile));
String HTMLOutputFile = "..";
SearchDetails search = new
SearchDetails(pageFile,HTMLOutputFile);
search.createReport();
}
catch(Exception e)
{
System.out.println("Properties file not found");
}
}
}
All this does is create the Properties object required for the processing by creating an HTML file (again this is shown by two dots) and then creating spider program. the report within the HTML file.
Before leaving the case study program it is worth saying that it is capable of accessing only relatively simple web pages. If, for example, a web page contained frames (a number of different panes on the same window) then the program would not work correctly.
Java Assignment Help - Java Homework Help
Struggling with java programming language? Are you not finding solution for your Case study: A spider homework and assignments? Live Case study: A spider experts are working for students by solving their doubts & questions during their course studies and training program. We at Expertsmind.com offer Case study: A spider homework help, java assignment help and Case study: A spider projects help anytime from anywhere for 24x7 hours. Computer science programming assignments help making life easy for students.
Why Expertsmind for assignment help
- Higher degree holder and experienced experts network
- Punctuality and responsibility of work
- Quality solution with 100% plagiarism free answers
- Time on Delivery
- Privacy of information and details
- Excellence in solving java programming language queries in excels and word format.
- Best tutoring assistance 24x7 hours